This system was developed over the course of several months for an organization that was performing high-thoughput screening services for clients. The system was designed with flexibility to accomodate a variety of screening modalities and data processing rules.
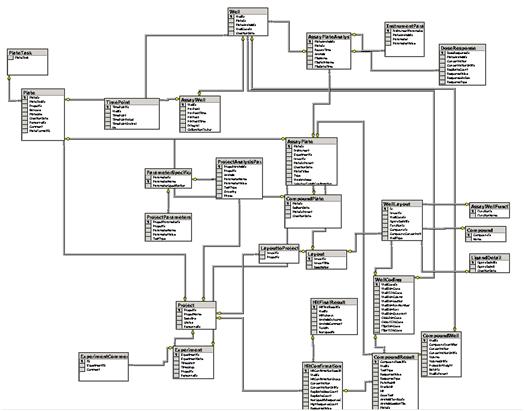
The data system was built around a custom SQL Server database. The database schema (right) was designed to allow the capture of all raw data, using custom import tools to read data produced by several different HTS readers.
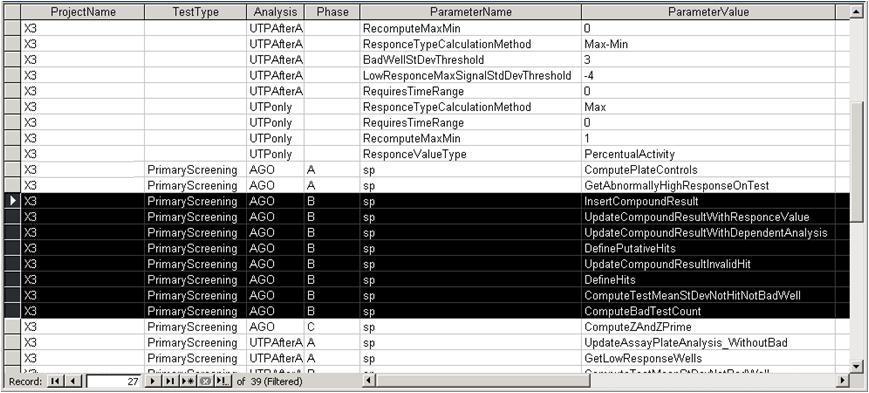
We created a unique mechanism to apply processing rules to this data. For each project, we could define data processing rules that would be applied, with different options for each step (see below). These rules were implemented as datapase stored procedures. The rules encompassed the definition of the response value(s), how to produce mean response, any data corrections to apply, computation of the biological response (e.g. %Inhibition), and definition of putative hit compounds. The rules allowed us to create completely different approaches to processing data from different biological assays. This was required to allow for the widely different assay formats used by the company. For example, some assays were confgures as simple end-point absorbance readings, while others were kinetic responses after injection of a compound and a subsequent agonist. The flexible processing rules allowed production of multiple response values for each compound tested.
Other components of this system included: automatic import and processing agents running on the HTS instruments, and the exposure of the results into the Spotfire DecisionSite data analysis package.
Spotfire was used for the graphical view of the results...